在 AI 代码生成能力快速提升的时代,一些原本需要大量人工投入的复杂工程问题,已经可以通过“工作流拆分 + AI 代码生成/优化 + AI 辅助验证”的方式逐步完成。
在特定 HIL 场景下,系统往往不仅仅是单一硬件平台的独立运行,而是需要多种不同架构的硬件进行协同交互。这里以 MCU-FPGA 架构为例。
MCU-FPGA 架构通常出现在这样一类场景中:系统同时存在高频实时计算、高精度求解、大矩阵计算或强并行计算需求,单靠 MCU 很难满足实时性和算力要求。因此,FPGA 会作为系统中的“特种兵”,承担其中最重、最难、最需要并行加速的部分。
但 FPGA 的开发体系与传统 MCU/CPU 体系并不相同。MCU 侧通常基于 C 语言和 CPU 内存执行模型进行开发,而 FPGA 侧则更多依赖 HDL 或 HLS 工具链,本质上是在描述硬件结构和并行计算逻辑。这也带来了更高的开发门槛、更复杂的时序约束,以及更难排查的工程问题。
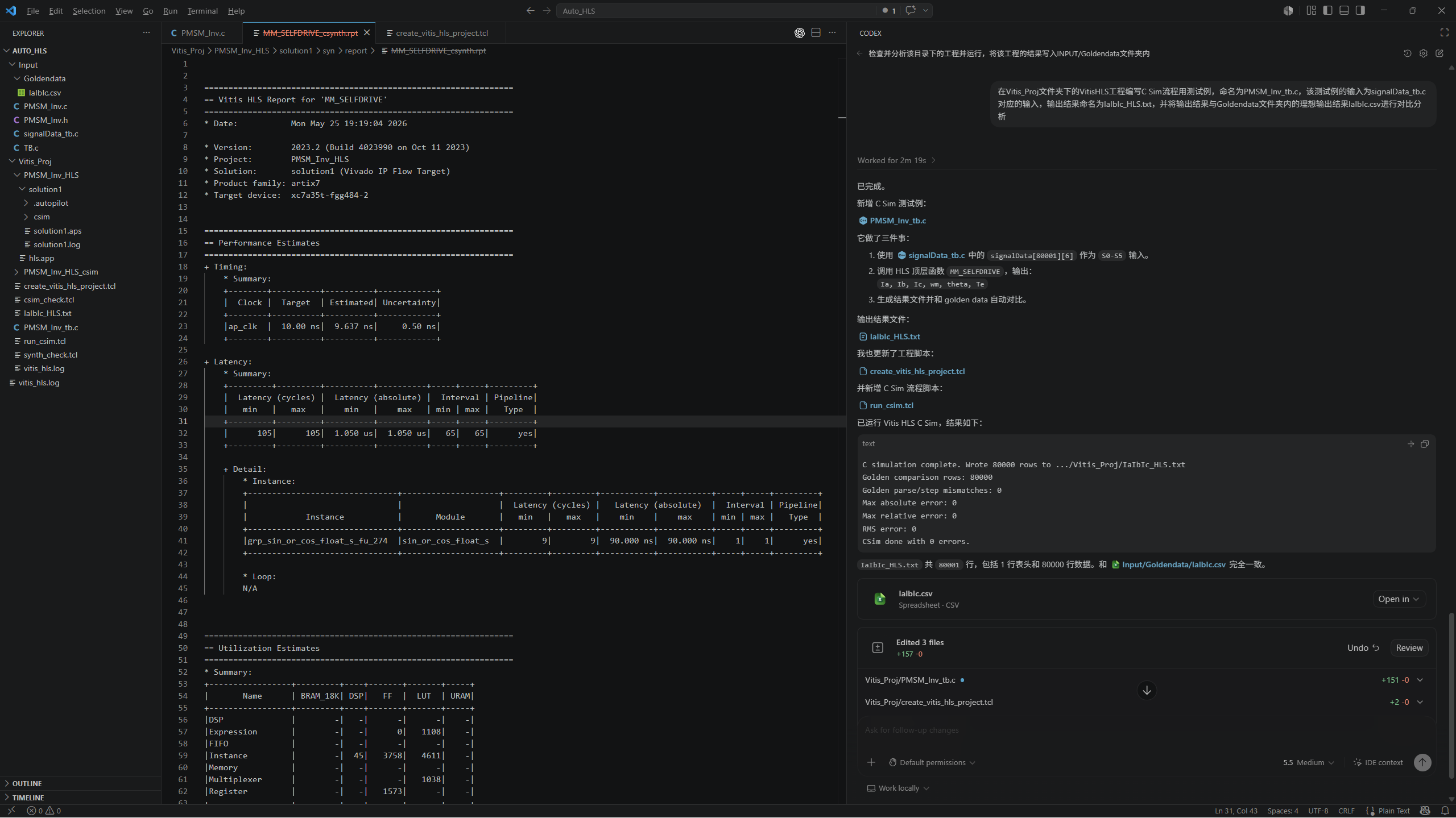
而 AI 的价值,恰恰可以体现在这个过程中:它不一定能完全替代 FPGA 工程师,也不一定能直接生成最终可商品化的硬件方案,但它可以在代码生成、结构拆分、接口设计、测试用例构造、通信逻辑验证、仿真结果比对等环节显著提高开发效率。以一个简单的闭环 PMSM-FOC 速度环控制 HIL 场景为例,我在工作中通常会按照以下链路推进整个工程从设计到落地:
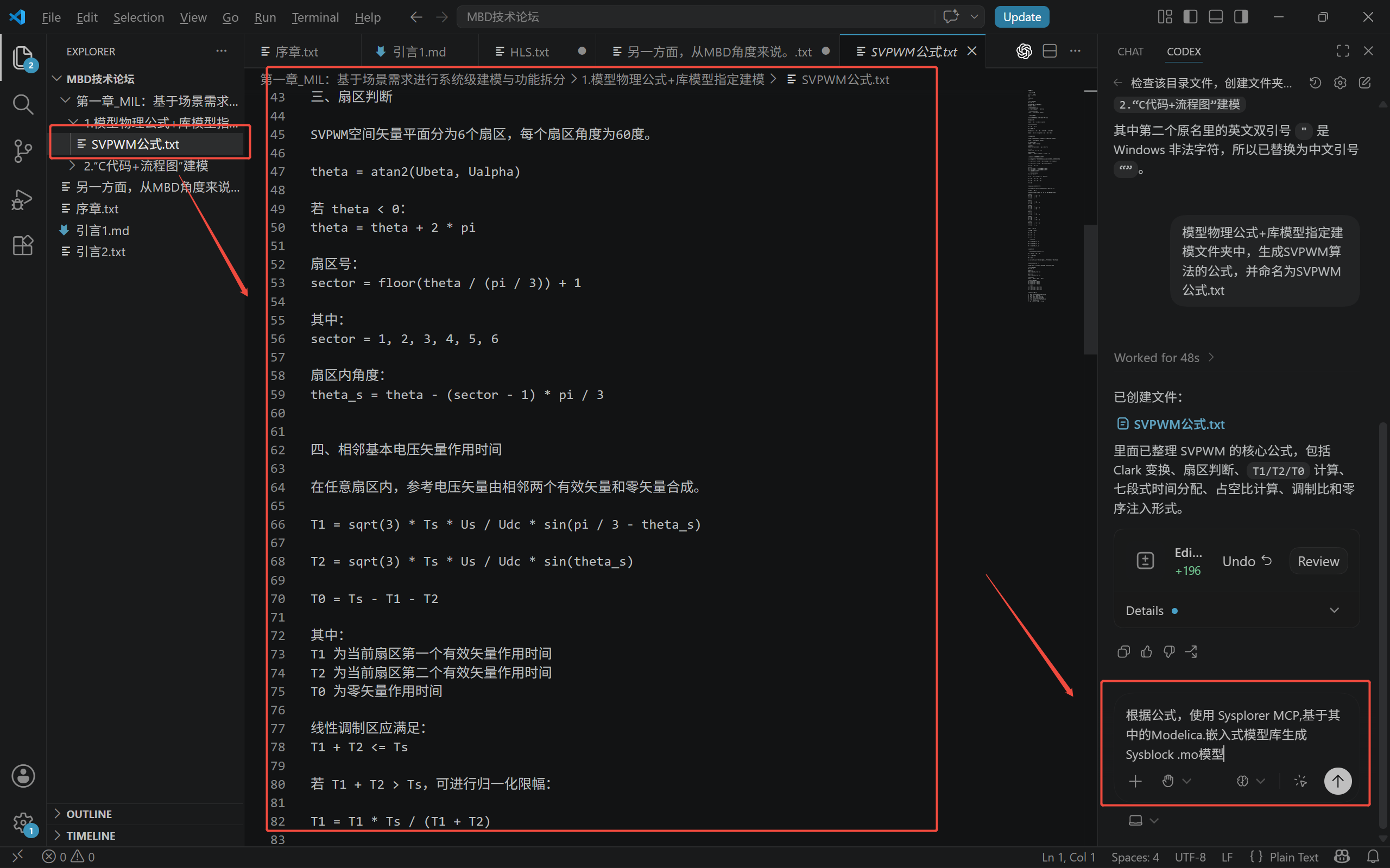
基于场景需求进行系统级建模与功能拆分
完成 MIL 仿真,对控制逻辑和对象模型进行初步验证
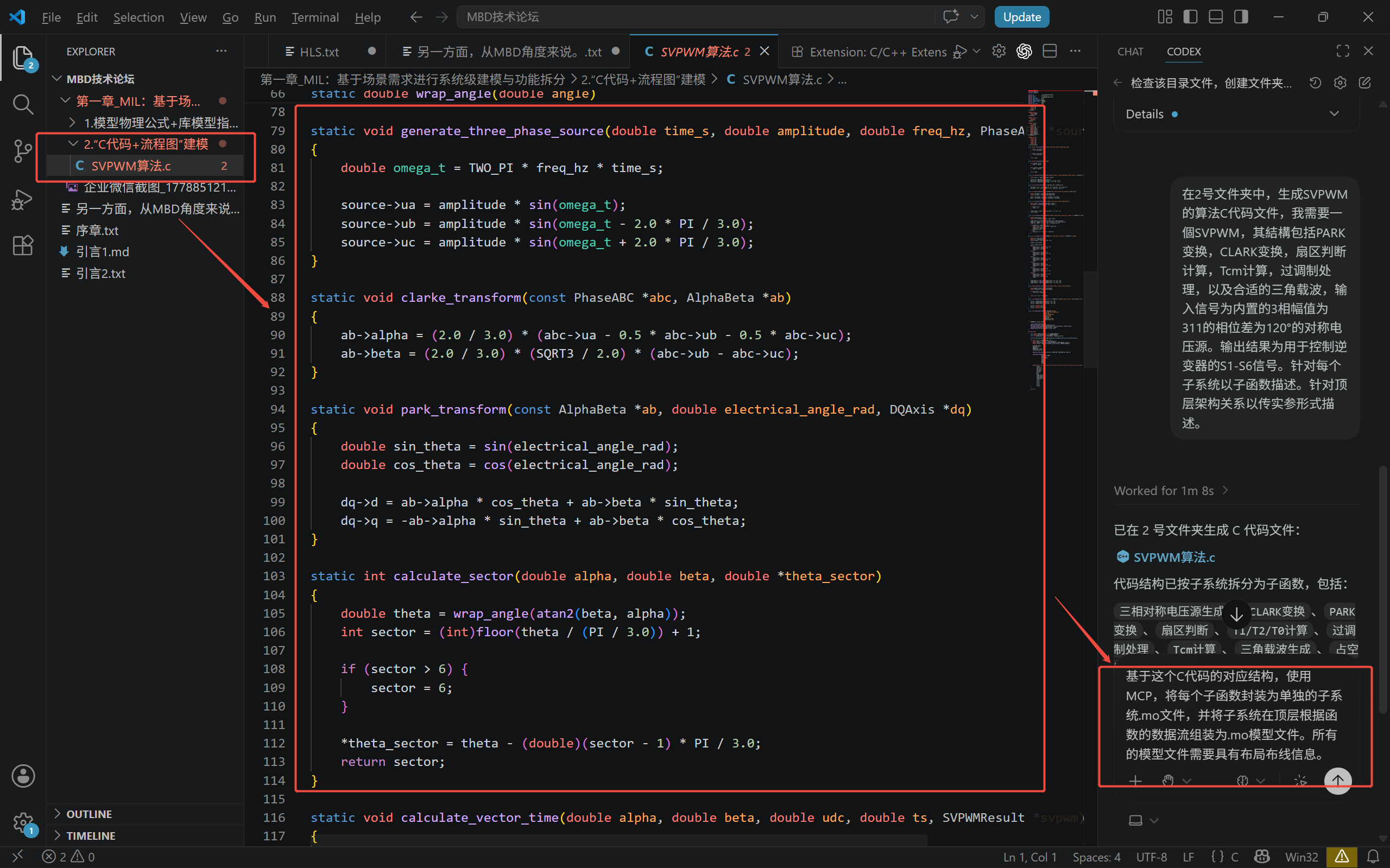
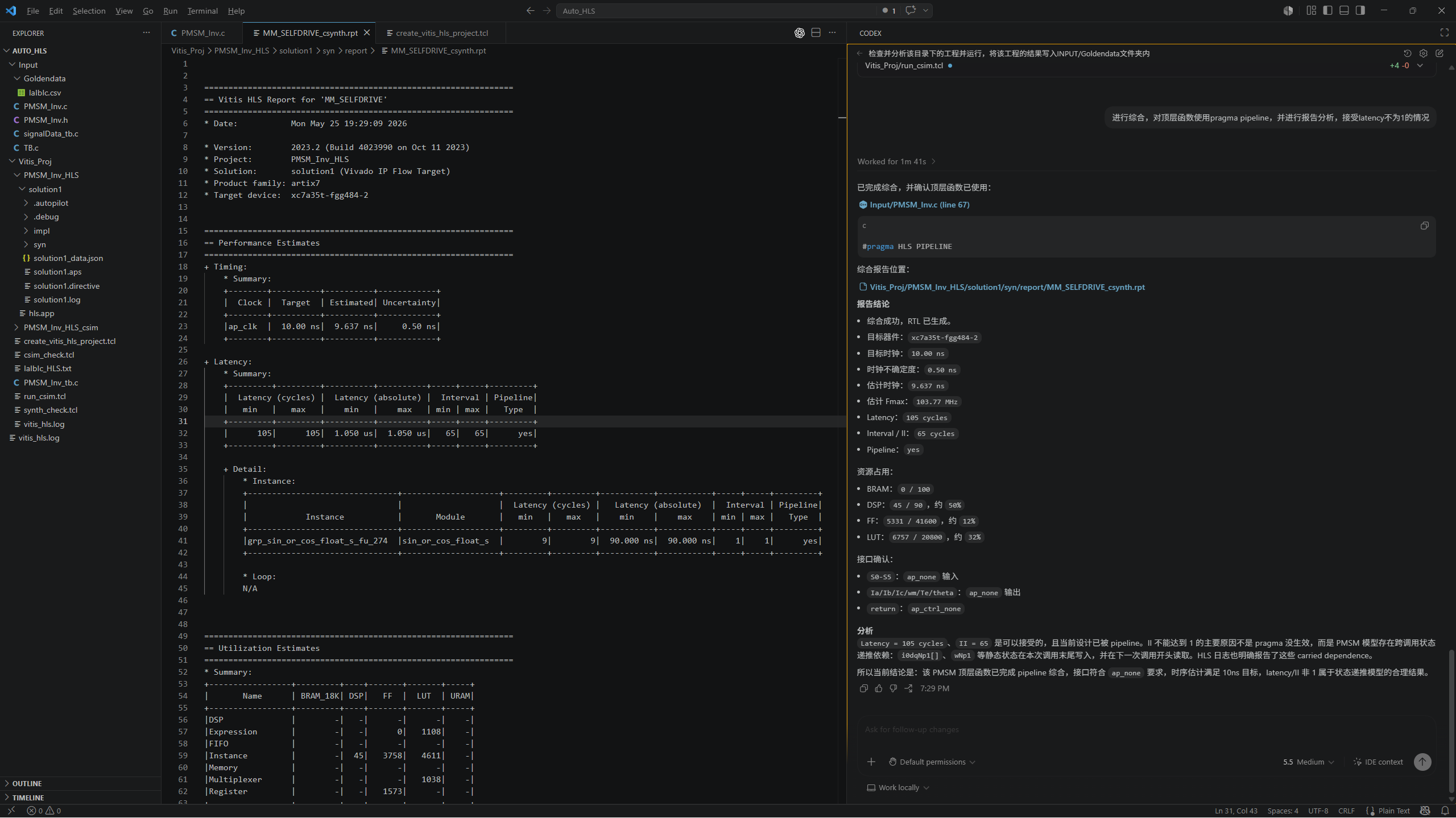
进行 FPGA 侧算法结构优化和实时性优化
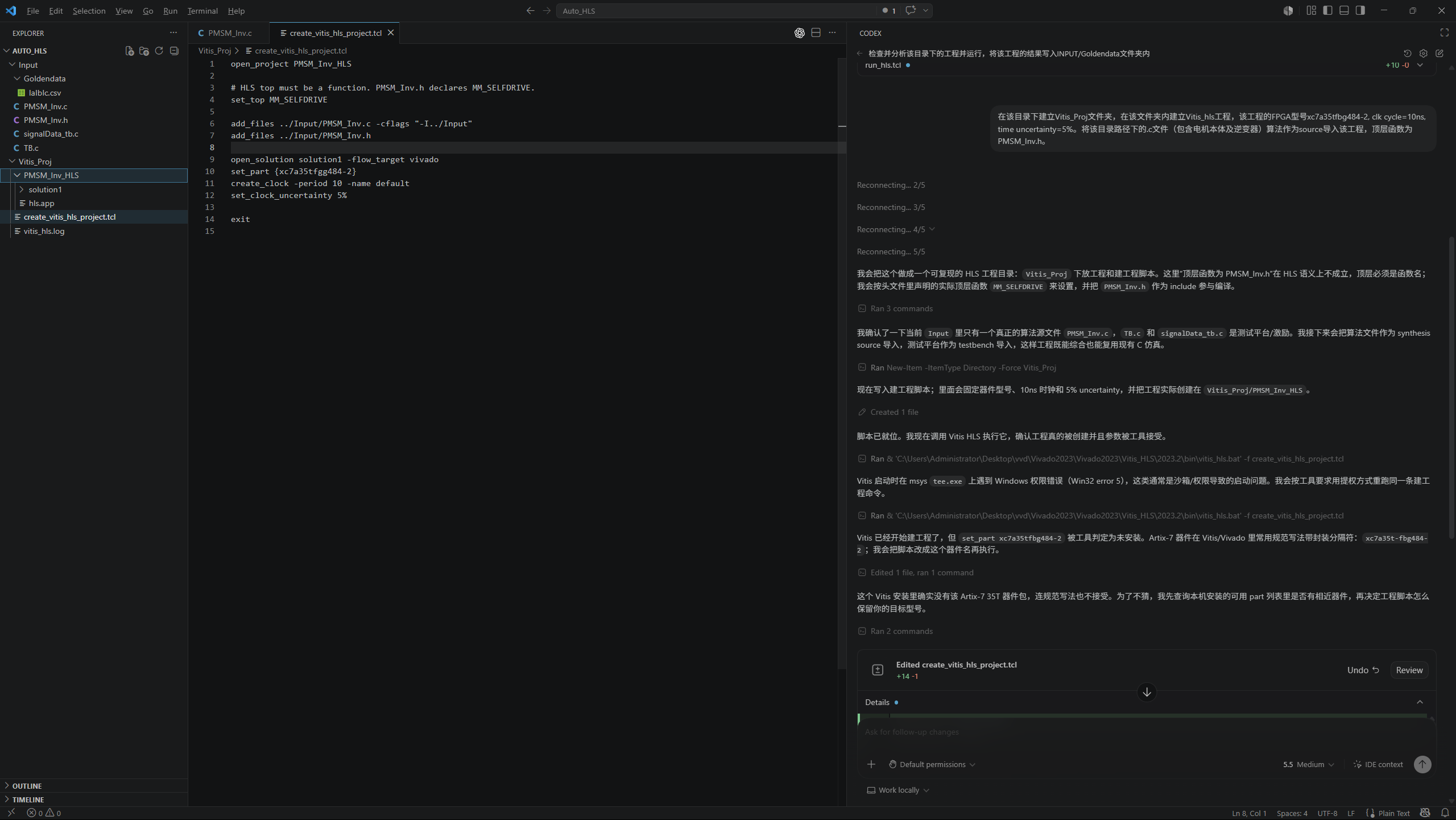
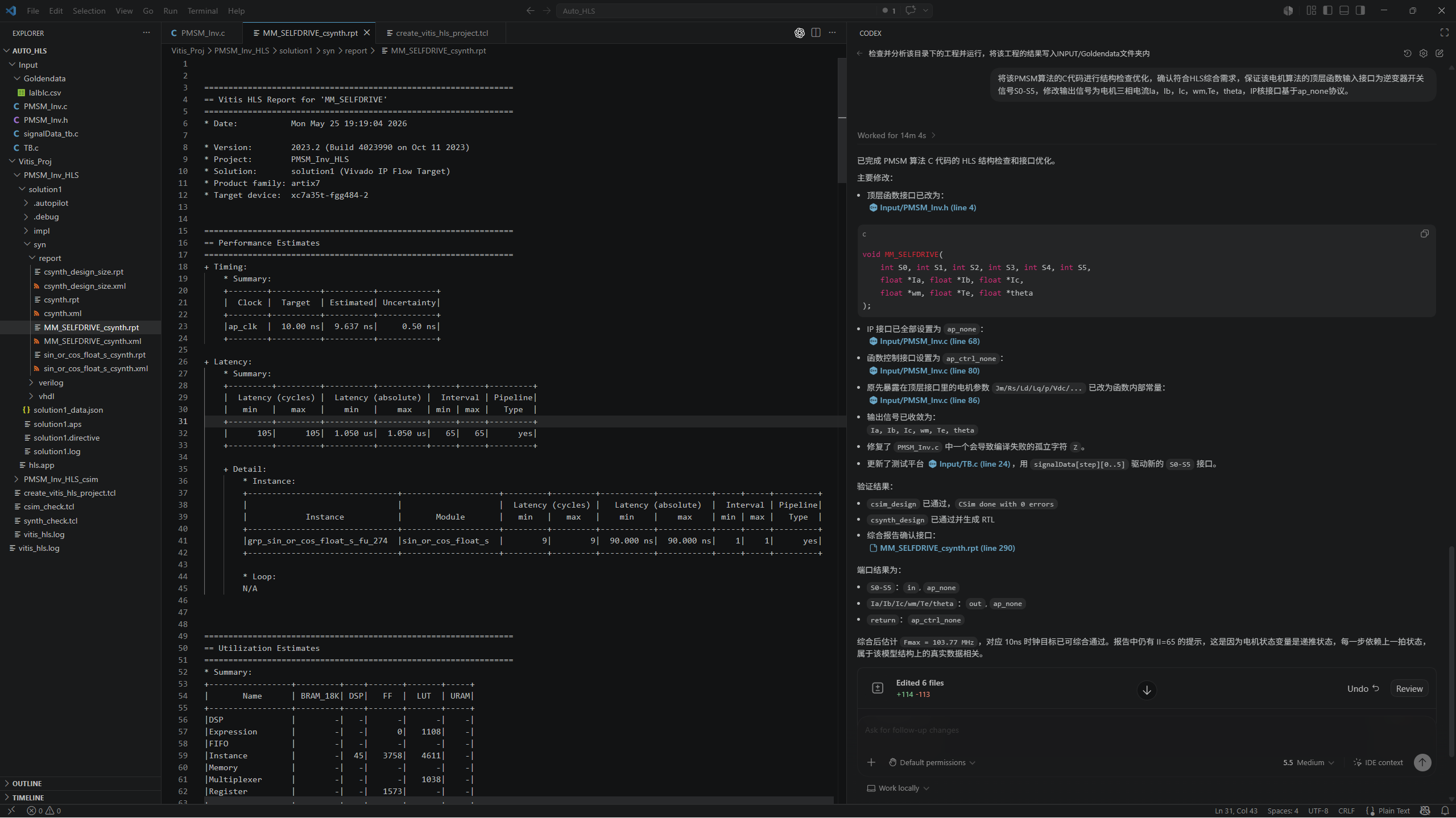
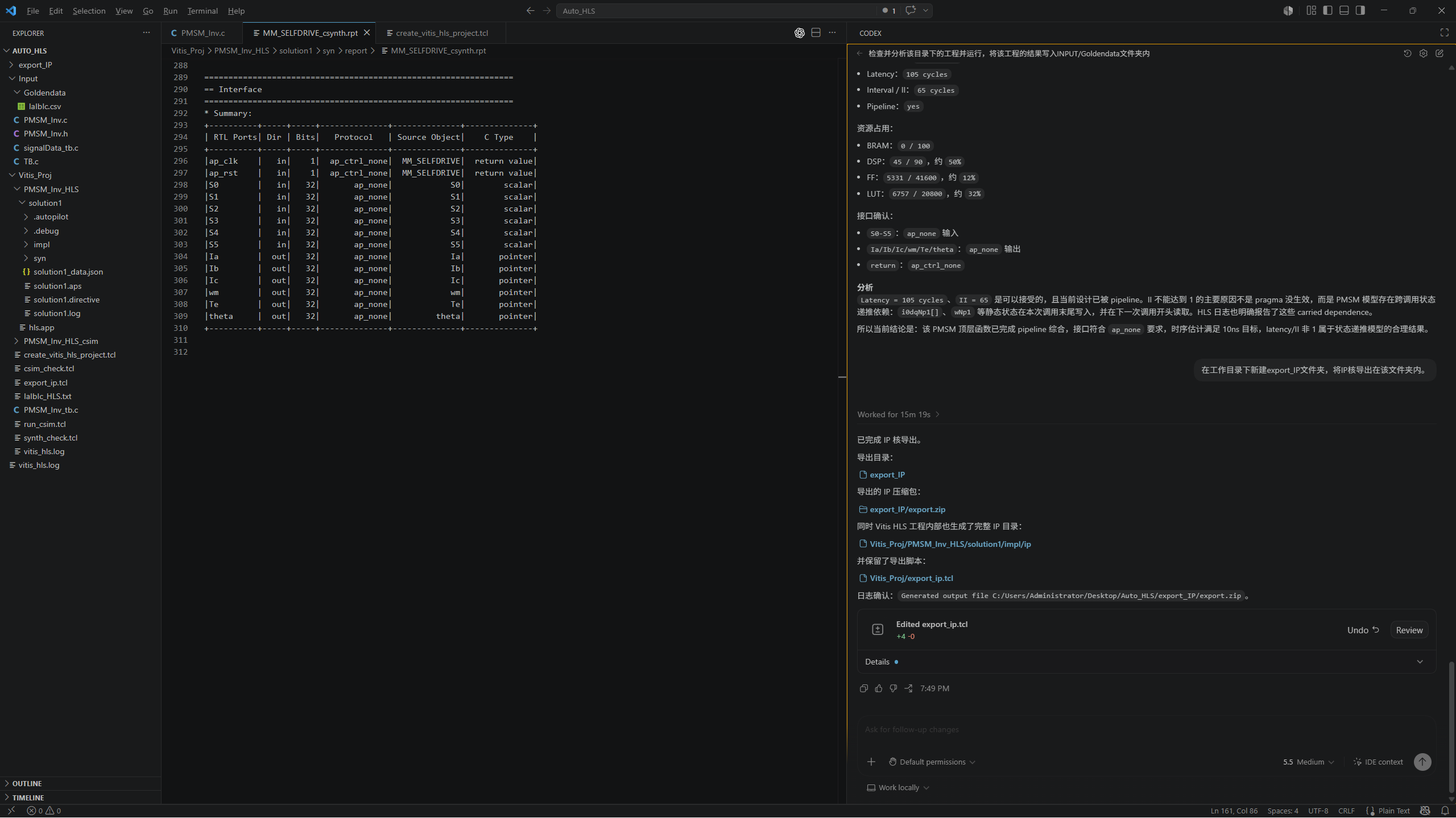
完成 FPGA 侧工程验证,包括综合、时序、接口和仿真验证
设计 FPGA 顶层结构、通信接口,并完成硬件落地
进行 MCU 侧控制算法优化和资源适配
完成 MCU 侧顶层设计、通信逻辑设计及工程落地
进行硬件级闭环 HIL 仿真验证,完成 MCU-FPGA-被控对象之间的闭环测试
在展开这条完整工程链路之前,我会先单独讨论两个和 FPGA 开发强相关的问题,也算是自己在工作中的一些阶段性心得:
FPGA 代码生成:AI 能做到什么,做不到什么
HLS 的意义:为什么它不是简单的“C 语言转 HDL”,但依然有工程价值
后续会围绕这两个问题展开,再结合 MCU-FPGA 异构 HIL 的具体工程链路,聊一聊 AI 时代下这类工程问题的开发方式会发生哪些变化。
本帖不讨论ZYNQ架构。
'%3e%3cg%20id='Group'%3e%3cpath%20id='Vector'%20d='M12%2012.0002C13.933%2012.0002%2015.5%2010.4331%2015.5%208.50009C15.5%206.56705%2013.933%205%2012%205C10.067%205%208.5%206.56705%208.5%208.50009C8.5%2010.4331%2010.067%2012.0002%2012%2012.0002Z'%20fill='white'%20stroke='white'%20stroke-width='1.40002'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20id='Vector_2'%20d='M19.5%2021.6877C19.5%2019.6985%2018.7098%2017.7908%2017.3033%2016.3843C15.8968%2014.9777%2013.9891%2014.1875%2012%2014.1875C10.0109%2014.1875%208.10322%2014.9777%206.6967%2016.3843C5.29018%2017.7908%204.5%2019.6985%204.5%2021.6877'%20stroke='white'%20stroke-width='1.87503'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20id='Vector_3'%20d='M12%2014.1875C10.0109%2014.1875%208.10322%2014.9777%206.6967%2016.3843C5.29018%2017.7908%204.5%2019.6985%204.5%2021.6877H19.5C19.5%2019.6985%2018.7098%2017.7908%2017.3033%2016.3843C15.8968%2014.9777%2013.9891%2014.1875%2012%2014.1875Z'%20fill='white'%20stroke='white'%20stroke-width='1.87503'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3c/g%3e%3crect%20x='2.15'%20y='2.15'%20width='19.7'%20height='19.7'%20rx='9.85'%20stroke='%23F96A02'%20stroke-width='0.3'/%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_474_37108'%3e%3crect%20x='2'%20y='2'%20width='20'%20height='20'%20rx='10'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
'%3e%3cg%20id='Group%201882'%3e%3cg%20id='Group%201881'%3e%3cpath%20id='Vector'%20d='M16.3334%202.02441H1.66675V14.5244H6.91675L9.00008%2016.6077L11.0834%2014.5244H16.3334V2.02441Z'%20stroke='white'%20stroke-width='1.25'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cpath%20id='&%23239;&%23188;&%23159;'%20d='M9.13224%203.95443C9.90024%203.95443%2010.5242%204.15843%2011.0042%204.59043C11.4842%205.01043%2011.7242%205.58643%2011.7242%206.30643C11.7242%206.89443%2011.5682%207.38643%2011.2682%207.77043C11.1602%207.90243%2010.8242%208.21443%2010.2602%208.70643C10.0322%208.89843%209.86424%209.11443%209.75624%209.33043C9.62424%209.57043%209.56424%209.83443%209.56424%2010.1224V10.3264H8.28024V10.1224C8.28024%209.67843%208.35224%209.29443%208.52024%208.98243C8.67624%208.64643%209.13224%208.15443%209.87624%207.49443L10.0802%207.26643C10.2962%206.99043%2010.4162%206.70243%2010.4162%206.39043C10.4162%205.97043%2010.2962%205.64643%2010.0682%205.40643C9.82824%205.16643%209.48024%205.04643%209.04824%205.04643C8.50824%205.04643%208.11224%205.21443%207.87224%205.56243C7.65624%205.85043%207.54824%206.25843%207.54824%206.78643H6.28824C6.28824%205.91043%206.54024%205.22643%207.04424%204.72243C7.54824%204.20643%208.24424%203.95443%209.13224%203.95443ZM8.91624%2010.9744C9.16824%2010.9744%209.38424%2011.0464%209.55224%2011.2144C9.72024%2011.3704%209.80424%2011.5744%209.80424%2011.8264C9.80424%2012.0784%209.70824%2012.2824%209.54024%2012.4504C9.37224%2012.6064%209.15624%2012.6904%208.91624%2012.6904C8.67624%2012.6904%208.46024%2012.6064%208.29224%2012.4384C8.12424%2012.2704%208.04024%2012.0664%208.04024%2011.8264C8.04024%2011.5744%208.12424%2011.3704%208.29224%2011.2144C8.46024%2011.0464%208.67624%2010.9744%208.91624%2010.9744Z'%20fill='white'/%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_387_16301'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e) 我要发帖
我要发帖  资料中心
资料中心 '%20stroke='url(%23paint1_linear_641_37213)'%20stroke-width='1.83333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20id='Vector_2'%20d='M7.38135%208.58811C7.38135%207.2561%208.46118%206.17627%209.79319%206.17627C11.1252%206.17627%2012.205%207.2561%2012.205%208.58811C12.205%209.92012%2011.1252%2011%209.79319%2011V12.4471'%20stroke='white'%20stroke-width='1.83333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20id='Vector_3'%20d='M9.79492%2015.3398V15.8222'%20stroke='white'%20stroke-width='1.83333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_641_37213'%20x1='11'%20y1='1.83496'%20x2='11'%20y2='20.165'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23FF9849'/%3e%3cstop%20offset='1'%20stop-color='%23FF6705'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_641_37213'%20x1='11'%20y1='1.83496'%20x2='11'%20y2='20.165'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23FF9849'/%3e%3cstop%20offset='1'%20stop-color='%23FF6705'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e) FAQ
FAQ '%3e%3cg%20id='Group%201880'%3e%3cpath%20id='Vector'%20d='M10.9997%2020.1654C16.0623%2020.1654%2020.1663%2016.0613%2020.1663%2010.9987C20.1663%205.93609%2016.0623%201.83203%2010.9997%201.83203C5.93706%201.83203%201.83301%205.93609%201.83301%2010.9987C1.83301%2012.2416%202.08036%2013.4267%202.52851%2014.5074C2.7599%2015.0654%203.04482%2015.5956%203.37687%2016.0917C3.48831%2016.2581%203.27925%2017.3105%202.74967%2019.2487C4.68792%2018.7191%205.74025%2018.51%205.90672%2018.6215C6.40273%2018.9535%206.93293%2019.2385%207.49095%2019.4698C8.5717%2019.918%209.75681%2020.1654%2010.9997%2020.1654Z'%20fill='url(%23paint0_linear_369_8392)'%20stroke='url(%23paint1_linear_369_8392)'%20stroke-width='1.83333'%20stroke-linejoin='round'/%3e%3cpath%20id='Vector_2'%20d='M7.61035%209.08398H15.3009'%20stroke='white'%20stroke-width='1.83333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20id='Vector_3'%20d='M10.0132%207.21289L8.67773%2014.7866'%20stroke='white'%20stroke-width='1.83333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20id='Vector_4'%20d='M13.2212%207.21289L11.8857%2014.7866'%20stroke='white'%20stroke-width='1.83333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20id='Vector_5'%20d='M6.69434%2012.832H14.3848'%20stroke='white'%20stroke-width='1.83333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_369_8392'%20x1='10.9997'%20y1='1.83203'%20x2='10.9997'%20y2='20.1654'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23FF9849'/%3e%3cstop%20offset='1'%20stop-color='%23FF6705'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_369_8392'%20x1='10.9997'%20y1='1.83203'%20x2='10.9997'%20y2='20.1654'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23FF9849'/%3e%3cstop%20offset='1'%20stop-color='%23FF6705'/%3e%3c/linearGradient%3e%3cclipPath%20id='clip0_369_8392'%3e%3crect%20width='22'%20height='22'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e) 热门帖子
热门帖子 '/%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_369_8417'%20x1='11'%20y1='2.5'%20x2='11'%20y2='19.5'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23FF9849'/%3e%3cstop%20offset='1'%20stop-color='%23FF6705'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e) 主要贡献者
主要贡献者